It is not unreasonable to speculate on what the future of software engineering will look like in the next 50 years. Software engineering is still a young discipline, with almost a half of a century since the coining of “software engineering”. Although we could claim some sort of success by simply pointing out the software underlying almost every facet of today’s world, that success has not been consistently repeatable nor teachable. As we become dependent on trillions lines of code in the next 50 years, there is little comfort we still have no fundamental scientific understanding of how to create software.
TL;DR This post will speculate on possible directions and the challenges faced by the research and software engineering community that needs to start now in order to be relevant tomorrow. Read on for brains, massive engineering, and potty-training your programs…
A different kind of engineering
Many of the challenges faced by humanity in the next decades will require software that works at completely different scales and completely different constraints than today’s software. Previously, we’ve been able to make the distinction between programming-in-the-large and programming-in-the-small, when reasoning about the size of teams and types of tools needed to build software. While software continues to fit these situations, it is already diverging from these categories in several ways.
Massively distributed software engineering
To meet the grand challenges of humanity, we will have to learn to massively scale software development in entirely new ways or die trying.
The development of the Large Hadron Collider’s core software system spanned over two decades, with over 50 million lines of code. Given enough time and dedication, we can create successfully massively large software systems.
But, we also may be reaching our limit given our current methods and capabilities. In the United States, the recent software behind the health care insurance marketplace is a reported 500 million lines of code.
In the next 50 years, as governments increasingly turn legal policy and services into source code and public APIs, often created in the timespan of a president’s term, we must be prepared to build massively-sized software systems on a regular basis. This will often require cooperation of many diverse stakeholders.
Why it sucks
Software companies, such as Microsoft, create documentation for millions of topics concerning its APIs, services, and software platforms (MSDN).
Creating this documentation comes at a considerable cost and effort. And after all this effort much documentation is rarely consulted (Lethbridge). API documentation is especially difficult to create (Robillard): as just a few writers must create documentation that teaches concepts and that maximally covers the many ways the thousands to millions of developers may be using their API.
Now, the trend may shift even more of the undocumented burden onto developers. The YouTube API recently moved their official developers support
from Google Groups to Stack Overflow (Move)— relying on a few thousand questions about the API and on mechanisms of Stack Overflow.
And there is no sign in sight that documentation is all the sudden going to get better.
Developers revolt
Instead, developers have been indirectly documenting APIs themselves through a process called crowd documentation, by publishing blog posts and curating questions and answers about APIs.
We previously found that even without any inherent coordination, a crowd of Android developers can cover as much as 88% of the API classes in discussions on Stack Overflow.
We collected 1,316 days of Android developer history (average 11 weeks per developer) and we found 9,234 visits to stackoverflow, as well as 2,547 to developer.android.com, which hosts the official documentation for Android. We also analyzed the code examples that could be found in the Stack Overflow data dump and developer.android.com/guide.
In our new study, we find that:
- Developers may be getting as much as 50% of their documentation from Stack Overflow.
- More examples can be found on Stack Overflow than the official documentation guide.
- In web searches, Stack Overflow questions are visited 2x-10x more often than official documentation.
I’m writing this post in an apt state: low-sleep, busy, disorientated, and interrupted.
I try all the remedies: Pomodoro, working in coffee shops, headphones,
and avoiding work until being distraction free in the late night.
But it is only so long before interruption finds a way to pierce my protective bubble. Like you, I am programmer, interrupted. Unfortunately, our understanding of interruption and remedies for them are not too far from homeopathic cures and bloodletting leeches.
But what is the evidence and what can we do about it?
Every few months I still see programmers who are asked to not use headphones during work hours or are interrupted by meetings too frequently but have little defense against these claims. I also fear our declining ability to handle these mental workloads and interruptions as we age.
The costs of interruptions have been studied in office environments. An interrupted task is estimated to take twice as long and contain twice as many errors as uninterrupted tasks (Czerwinski:04). Workers have to work in a fragmented state as 57% of tasks are interrupted (Mark:05).
For programmers, there is less evidence of the
effects and prevalence of interruptions. Typically, the number that gets tossed around
for getting back into the “zone” is at least 15 minutes after an interruption.
Interviews with programmers produce a similiar number (vanSolingen:98).
Nevertheless, numerous figures have weighed in: Paul Graham stresses the differences between a maker’s schedule and manager’s schedule.
Jason Fried says the office is where we go to get interrupted.
Interruptions of Programmers
Based on a analysis of 10,000 programming sessions recorded from 86 programmers using Eclipse and Visual Studio and a survey of 414 programmers (Parnin:10), we found:
Software development isn’t just about the code we write. It also spans the many situations, experiences, and new knowledge we encounter when we write code.
Funny thing is we can’t seem to directly recall or reflect on that stuff very easily. This is no more apparent than we just finished a whole bunch coding and just seem to draw a blank when writing a commit message.
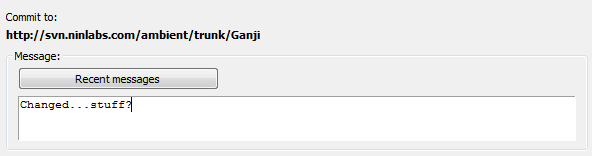
How can we improve a developer’s ability to recall and reflect over recent coding experiences? Can we keep better tally over our activities and even curate and share them?
Timelines
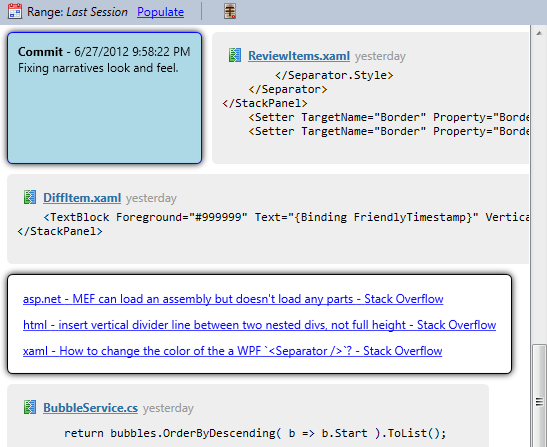
Timeline events include uncaught exceptions:
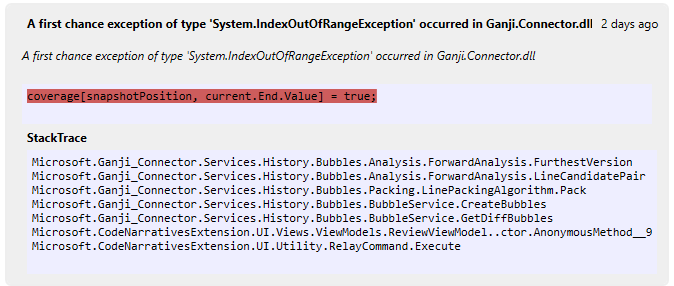
Collected History
How the system works: Every code change is submitted to a local git repository.
Uncaught exceptions and caught exceptions that hit a breakpoint are logged. Navigation, searches, code copied and pasted from the web are also logged. External data such as SVN/GIT repositories and local browser history are integrated into the history.
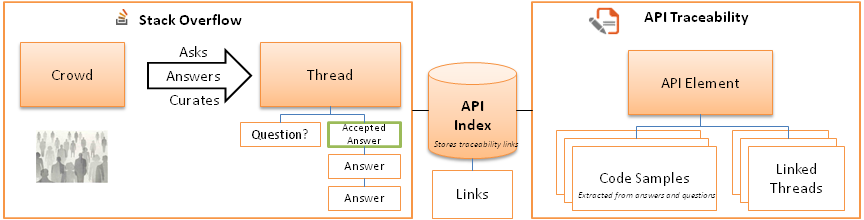 Traditional documentation requires a process where a few people write for many potential users (especially in the case of API documentation). The resulting documentation, more often than not just doesn’t cut it – There aren’t enough examples, details, or explanations.
Traditional documentation requires a process where a few people write for many potential users (especially in the case of API documentation). The resulting documentation, more often than not just doesn’t cut it – There aren’t enough examples, details, or explanations.
Crowd documentation turns the traditional documentation process on its head – knowledge is created and curated by a mostly uncoordinated collective. The potential is massive and already happening: stackoverflow.com allows users to ask and answer questions about programming topics, blog posts allow developers to write tutorials and provide solutions to otherwise undocumented issues. StackOverflow already has 3 million questions (with 85% percent answered in a median of 11 minutes) and countless number of blog posts have been written.
But a burning question remains, can we trust crowd documentation? Will it be complete, will it be fast, will it be authoritative? What type of content is created by the crowd and who contributes?
Analyzing API Discussions on Stackoverflow

To answer these questions, we obtained a data dump of the StackOverflow database and we measured the amount of discussion of different API elements, such as classes or methods, on StackOverflow.
We wanted to know:
-
Will different API elements be widely covered
-
If an API element is discussed infrequently is it also discussed infrequently in practice
-
How fast is the crowd at covering an entire API